Gymnasium by the Farama Foundation, which replaces the discontinued Gym by OpenAI, is a Python package with a standardized API for reinforcement learning. The image and the example below are taken from Gymnasium’s docs.
At its core, Gymnasium implements the typical Markov Decision Process cycle of “observe → think → act → get reward”:
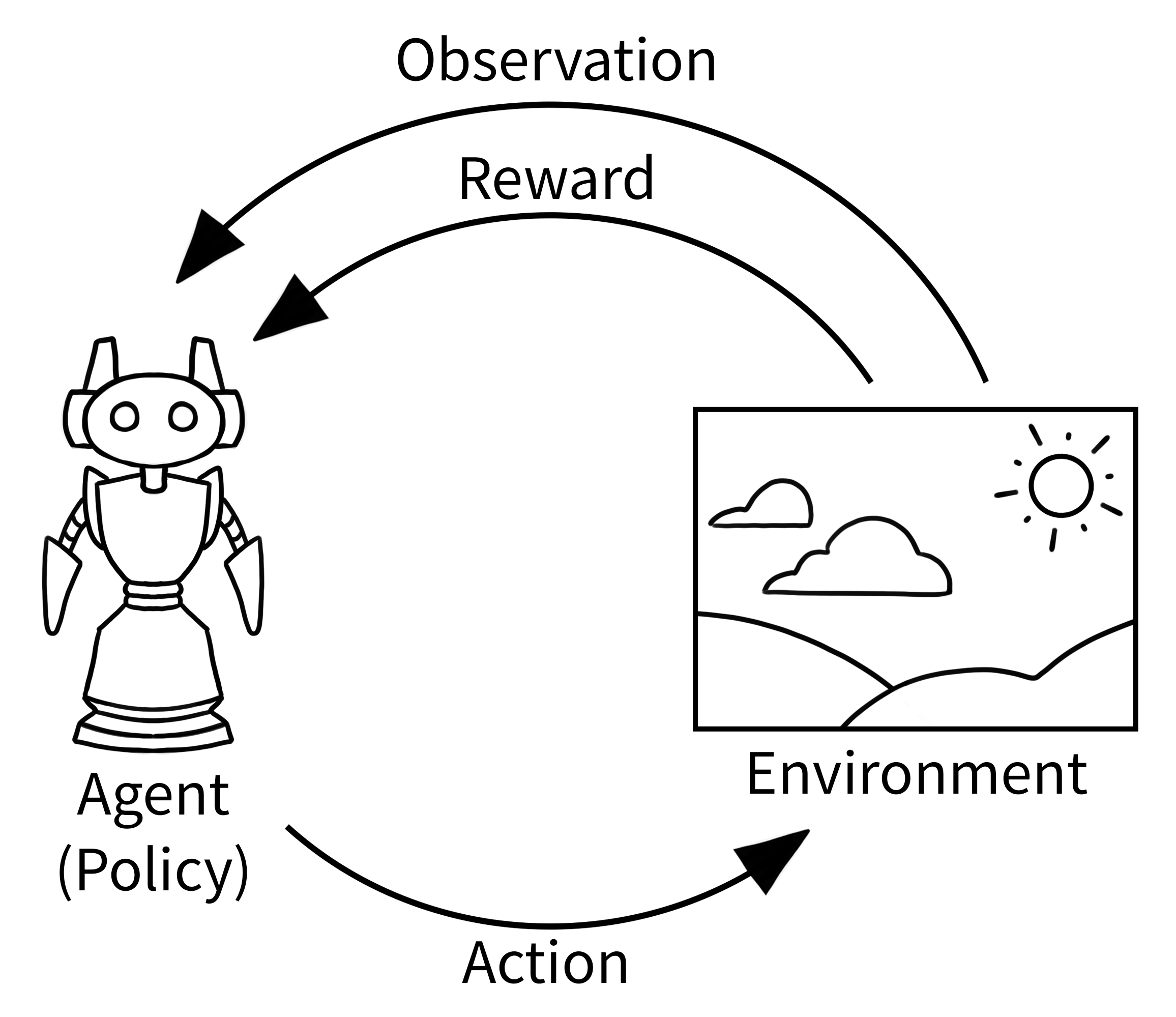
The MDP cycle standardized by Gymnasium environments#
the process is initialized
and updated iteratively:
the agent applies an action
and gets observation and reward
until the process ends
which, using the API, is typically implemented like
Environments include everything needed to run specific simulations. There are several available, ranging from Atari-like games to 3D robotics simulations.
PettingZoo also by the Farama Foundation, extends Gymnasium to multi-agent system. It support two API:
AEC, in which agents act one at the time, like in turn-based games;
Parallel, in which agents at the same time and is more suitable to interact with navground.
The Parallel API is similar to Gymnasium, with the difference that actions, rewards, observations, …, are indexed by an agent identifier:
importpettingzooaspzenvironment=MyMultiAgentEnviroment()observations,infos=environment.reset()for_inrange(1000):actions={index:evaluate_my_policy(observation)forindex,observationinobservations.items()}observations,rewards,terminations,truncations,infos=environment.step(actions)# Instead of looking at terminations and truncations# we can directly check that there are still some agents aliveifnotenv.agents:breakenv.close()
Note
We can convert between environments with AEC and Parallel API using
convertion wrappers.
Moreover, we can convert PettingZoo environments in which all agents share the same action and observation spaces to
a vectorized Gymnasium environment that concatenate all the actions, observations and other infos using SuperSuit wrappers. This way, we can use ML libraries that works with Gymanasium to train distributed multi-agent systems.
as navground.sim.World.update() groups together the steps of policy (in navground behavior) evaluation and actuation.
Navground simulations may features many diverse agents types, using different kinematics, tasks, state estimation, and navigation behaviors.
Note
Navground is extensible. You can implement new behaviors, tasks, scenarios and in particular new sensor models, in C++ or in Python.
Therefore, we can build a custom navigation environment for machine learning, where agents use a particular sensing models, by sub-classing navground.sim.Sensor.
env.NavgroundEnv wraps a navground.sim.Scenario in an gymnasium.Env that conforms to the standard API expected by gymnasium, with actions and observations linked to a single navground agent. In particular (with some simplifications):
instantiates a gymnasium environment whose worlds will be spawned using a navground scenario. If specified, the agent will use a sensor to generate observations, instead of its predefined state estimation. The action and observation spaces of the agent can be customized, for instance whether to include the distance to the target, or to control the agent orientation.
Similarly, parallel_env.MultiAgentNavgroundEnv provides a environment for which actions and observations are linked to a multiple navground agents.
parallel_env.parallel_env() instantiate an environment where different agents may use different configurations (such as action spaces, rewards, …), while
parallel_env.shared_parallel_env() instantiate an environment where all specified agents share the same configuration.
The rest of the functionality is very similar to the Gymnasium Environment (and in fact, they share the same base class), but conform to the PettingZoo API instead.
Have a look at the tutorials to see the interaction between gymnasium and navground in action and how to use it to train a navigation policy using IL or RL.
Using the navground environments, we can train a policy that imitates
one of the navigation behaviors implemented in navground, using any of the available sensors.
We include helper classes that wraps the Python package imitation by the Center for Human-Compatible AI
to offer simplified interface, yet nothing prevent to use the original API.
Using the navground-gymnasium environment, we can train a policy to navigate among other agents controlled by navground, for instance using the RL algorithm implemented in Stable-Baselines3 by
DLR-RM.
Using the multi-agent navground-gymnasium environment, we can train a policy in parallel for all agents in the environment, that is, the agents
learn to navigate among peers that are learning the same policy.
We instantiate the parallel environment using parallel_env.shared_parallel_env(), and transform it to a Stable-Baseline compatible (sigle-agent) vectorized environment using parallel_env.make_vec_from_penv(). While learning, from the view-point of the SAC algorithm, rollouts will generate by a single agent in n environments that compose venv, while in reality they will be generate in a single penv by n agents.
Evaluation can also be performed using the tools available in navground,
which are specifically designed to support large experiments with many runs and agents, distributing the work over multiple processor if desired.
Once we have trained a policy (and possibly exported it to onnx using onnx.export()), behaviors.PolicyBehavior executes it as a navigation behavior in navground. As a basic example, we can load it and assign it to some of the agents in the simulation:
importnavgroundassimimportgymnasiumasgymfromnavground.learning.behaviorsimportPolicyBehavior# we load the same scenario and sensor used to train the policyscenario=sim.Scenario.load(...)sensor=sim.Sensor.load(...)world=scenario.make_world(seed=1)# and configure the first five agents to use the policy# instead of the original behaviorforagentinworld.agents[:5]:agent.behavior=PolicyBehavior.clone_behavior(agent.behavior,policy='policy.onnx',action_config=...,observation_config=...)agent.state_estimation=sensorworld.run(time_step=0.1,steps=1000)
In practice, we do not need to perform the configuration manually. Instead, we can load it from a YAML file (exported e.g. using io.export_policy_as_behavior()), like common in navground:
groups:-number:5behavior:type:PolicyBehaviorpolicy_path:policy.onnx# action and observation config...state_estimation:# sensor config...# remaining of the agents config...
When loaded, the 5 agents in this group will use the policy to navigate
importnavgroundassim# loads the navground.learning components such as PolicyBehaviorsim.load_plugins()withopen('scenario.yaml')asf:scenario=sim.Scenario.load(f.read())world=scenario.make_world(seed=1)world.run(time_step=0.1,steps=1000)
or we could embed it in an experiment to record trajectories and performance metrics:
The work was supported in part by REXASI-PRO H-EU project, call HORIZON-CL4-2021-HUMAN-01-01, Grant agreement no. 101070028.
The work has been partially funded by the European Union. Views and opinions expressed are however those of the author(s) only and do not necessarily reflect those of the European Union or the European Commission. Neither the European Union nor the European Commission can be held responsible for them.